В области памяти для ассистентов ИИ текущая тенденция подразумевает использование больших моделей языка как для структурирования данных при их сохранении, так и для их извлечения. SmartSearch бросает вызов этой парадигме, демонстрируя, что почти полностью детерминированный pipeline может превосходить эти сложные системы. Он достигает превосходного извлечения информации в бенчмарках, таких как LoCoMo и LongMemEval-S, используя в 8,5 раза меньше токенов контекста и работая на CPU с задержками около 650 мс. Этот прорыв обещает более легкие, быстрые и масштабируемые разговорные ассистенты. 🤖
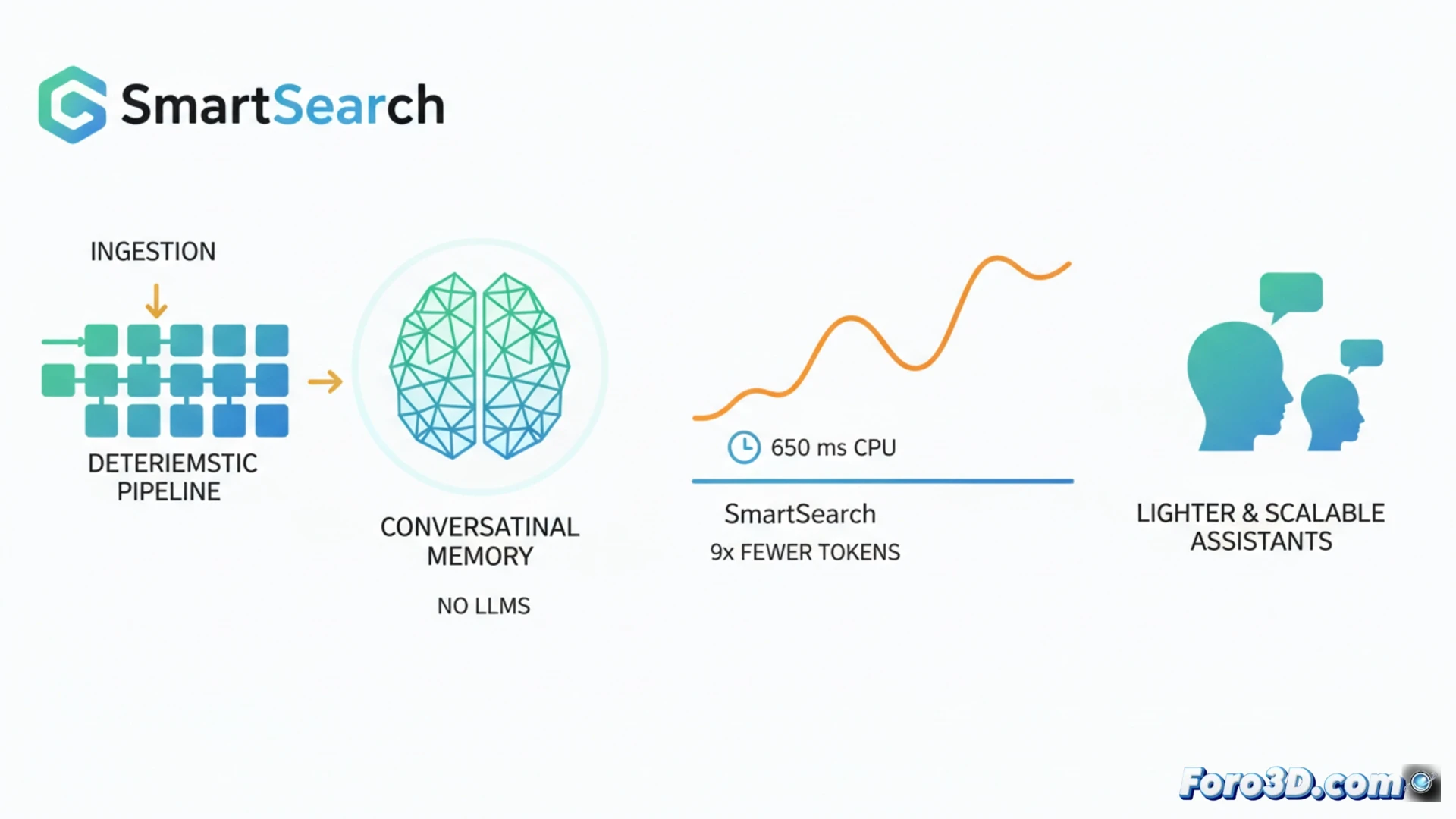
Детерминированный Pipeline для извлечения в разговорах 🔍
SmartSearch работает в три ключевых этапа. Сначала выполняется начальное извлечение с помощью сопоставления подстрок, взвешенного по релевантности обнаруженных именованных сущностей. Затем поиск расширяется мультипрыжковым способом с использованием простых правил для обнаружения связанных сущностей в истории без обработки. Наконец, единственный обучаемый компонент объединяет и переранжирует результаты: модель CrossEncoder+ColBERT, которая эффективно работает на CPU. Анализ показывает, что, хотя грубое извлечение отлично, узким местом является ранжирование; без их метода адаптивного усечения на основе оценки большинство релевантных доказательств потерялось бы при ограничении токенов.
Последствия для будущего с более легким ИИ ⚡
Успех SmartSearch ставит под сомнение необходимость тяжелых и дорогих архитектур для специфических функций, таких как разговорная память. Минимизируя зависимость от LLM во время ингестации и отдавая приоритет детерминированной эффективности, он прокладывает путь к более доступным и устойчивым системам ИИ. Это критически важно для интеграции интеллектуальных ассистентов в устройства с ограниченными ресурсами или приложения, требующие низкой задержки, демократизируя доступ к продвинутым разговорным возможностям без огромного текущего вычислительного следа.
Возможно ли построить эффективную и контекстную систему разговорной памяти без зависимости от дорогостоящей ингестации и структурирования с помощью LLM?
(PD: эффект Стрейзанд в действии: чем больше запрещаешь, тем больше используют, как microslop)