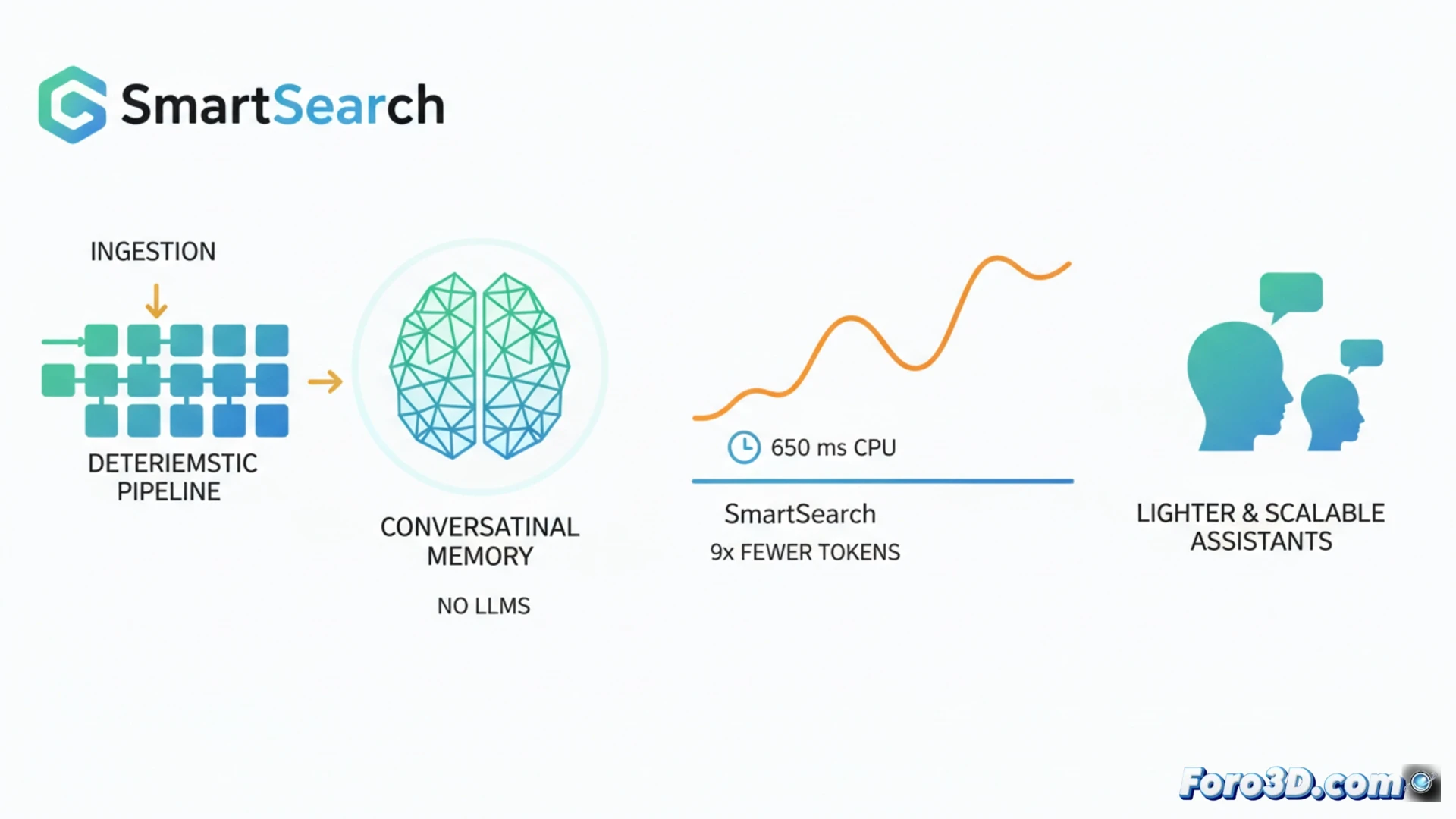
En el campo de la memoria para asistentes de IA, la tendencia actual implica usar modelos de lenguaje grandes tanto para estructurar los datos al guardarlos como para recuperarlos. SmartSearch desafía este paradigma al demostrar que un pipeline casi completamente determinista puede superar a estos sistemas complejos. Logra una recuperación de información superior en benchmarks como LoCoMo y LongMemEval-S, utilizando 8.5 veces menos tokens de contexto y ejecutándose en CPU con latencias alrededor de 650 ms. Este avance promete asistentes conversacionales más ligeros, rápidos y escalables. 🤖
Un Pipeline Determinista para la Recuperación en Conversaciones 🔍
SmartSearch opera en tres etapas clave. Primero, realiza una recuperación inicial mediante coincidencia de subcadenas, ponderada por la relevancia de las entidades nombradas detectadas. Luego, expande la búsqueda de forma multi salto usando reglas simples para descubrir entidades relacionadas en el historial sin procesar. Finalmente, un único componente aprendido fusiona y rerranquea los resultados: un modelo CrossEncoder+ColBERT que se ejecuta eficientemente en CPU. El análisis revela que, aunque la recuperación bruta es excelente, el cuello de botella está en el ranking; sin su método de truncamiento adaptativo basado en puntuación, la mayoría de la evidencia relevante se perdería al limitar los tokens.
Implicaciones para un Futuro con IA Más Ligera ⚡
El éxito de SmartSearch cuestiona la necesidad de arquitecturas pesadas y costosas para funciones específicas como la memoria conversacional. Al minimizar la dependencia de LLMs en tiempo de ingestión y priorizar la eficiencia determinista, establece un camino hacia sistemas de IA más accesibles y sostenibles. Esto es crucial para integrar asistentes inteligentes en dispositivos con recursos limitados o aplicaciones que requieren baja latencia, democratizando el acceso a capacidades conversacionales avanzadas sin la enorme huella computacional actual.
¿Es posible construir un sistema de memoria conversacional eficiente y contextual sin depender de la costosa ingestión y estructuración con LLMs?
(PD: el efecto Streisand en acción: cuanto más lo prohíbes, más lo usan, como el microslop)