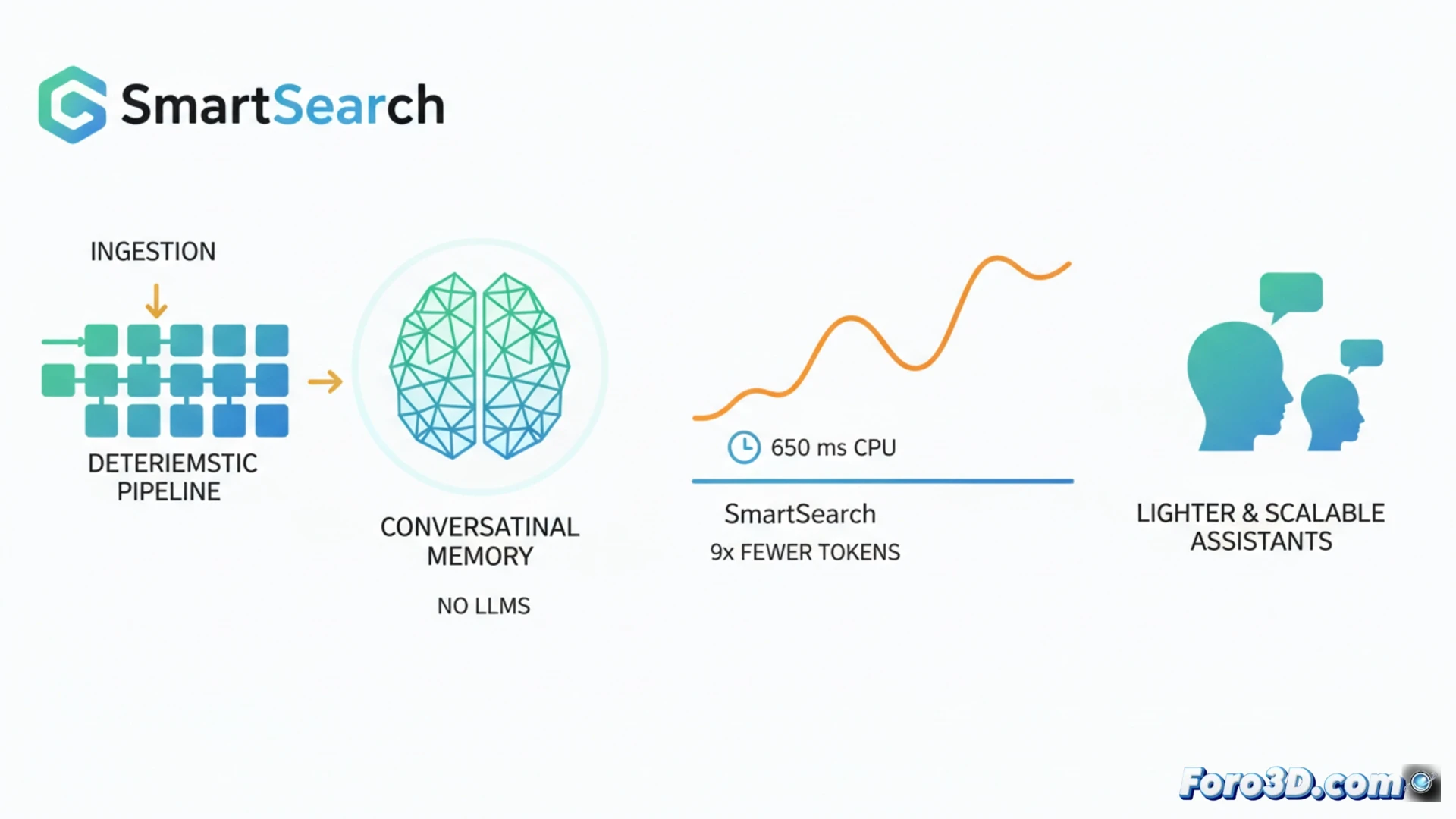
No campo da memória para assistentes de IA, a tendência atual implica usar modelos de linguagem grandes tanto para estruturar os dados ao armazená-los como para recuperá-los. SmartSearch desafia esse paradigma ao demonstrar que um pipeline quase completamente determinista pode superar esses sistemas complexos. Consegue uma recuperação de informação superior em benchmarks como LoCoMo e LongMemEval-S, utilizando 8,5 vezes menos tokens de contexto e executando-se em CPU com latências em torno de 650 ms. Esse avanço promete assistentes conversacionais mais leves, rápidos e escaláveis. 🤖
Um Pipeline Determinista para a Recuperação em Conversas 🔍
SmartSearch opera em três etapas principais. Primeiro, realiza uma recuperação inicial por meio de correspondência de subcadeias, ponderada pela relevância das entidades nomeadas detectadas. Em seguida, expande a busca de forma multi salto usando regras simples para descobrir entidades relacionadas no histórico sem processamento. Finalmente, um único componente aprendido funde e reordena os resultados: um modelo CrossEncoder+ColBERT que se executa eficientemente em CPU. A análise revela que, embora a recuperação bruta seja excelente, o gargalo está no ranking; sem seu método de truncamento adaptativo baseado em pontuação, a maioria das evidências relevantes seria perdida ao limitar os tokens.
Implicações para um Futuro com IA Mais Leve ⚡
O sucesso do SmartSearch questiona a necessidade de arquiteturas pesadas e custosas para funções específicas como a memória conversacional. Ao minimizar a dependência de LLMs no tempo de ingestão e priorizar a eficiência determinista, estabelece um caminho para sistemas de IA mais acessíveis e sustentáveis. Isso é crucial para integrar assistentes inteligentes em dispositivos com recursos limitados ou aplicações que requerem baixa latência, democratizando o acesso a capacidades conversacionais avançadas sem a enorme pegada computacional atual.
É possível construir um sistema de memória conversacional eficiente e contextual sem depender da custosa ingestão e estruturação com LLMs?
(PD: o efeito Streisand em ação: quanto mais você proíbe, mais eles usam, como o microslop)