AI 어시스턴트의 메모리 분야에서 현재 추세는 데이터를 저장할 때와 검색할 때 모두 대형 언어 모델을 사용하는 것입니다. SmartSearch는 거의 완전히 결정론적인 파이프라인이 이러한 복잡한 시스템을 능가할 수 있음을 입증함으로써 이 패러다임을 도전합니다. LoCoMo와 LongMemEval-S와 같은 벤치마크에서 우수한 정보 검색을 달성하며, 컨텍스트 토큰을 8.5배 적게 사용하고 CPU에서 약 650ms의 지연으로 실행됩니다. 이 발전은 더 가볍고 빠르며 확장 가능한 대화형 어시스턴트를 약속합니다. 🤖
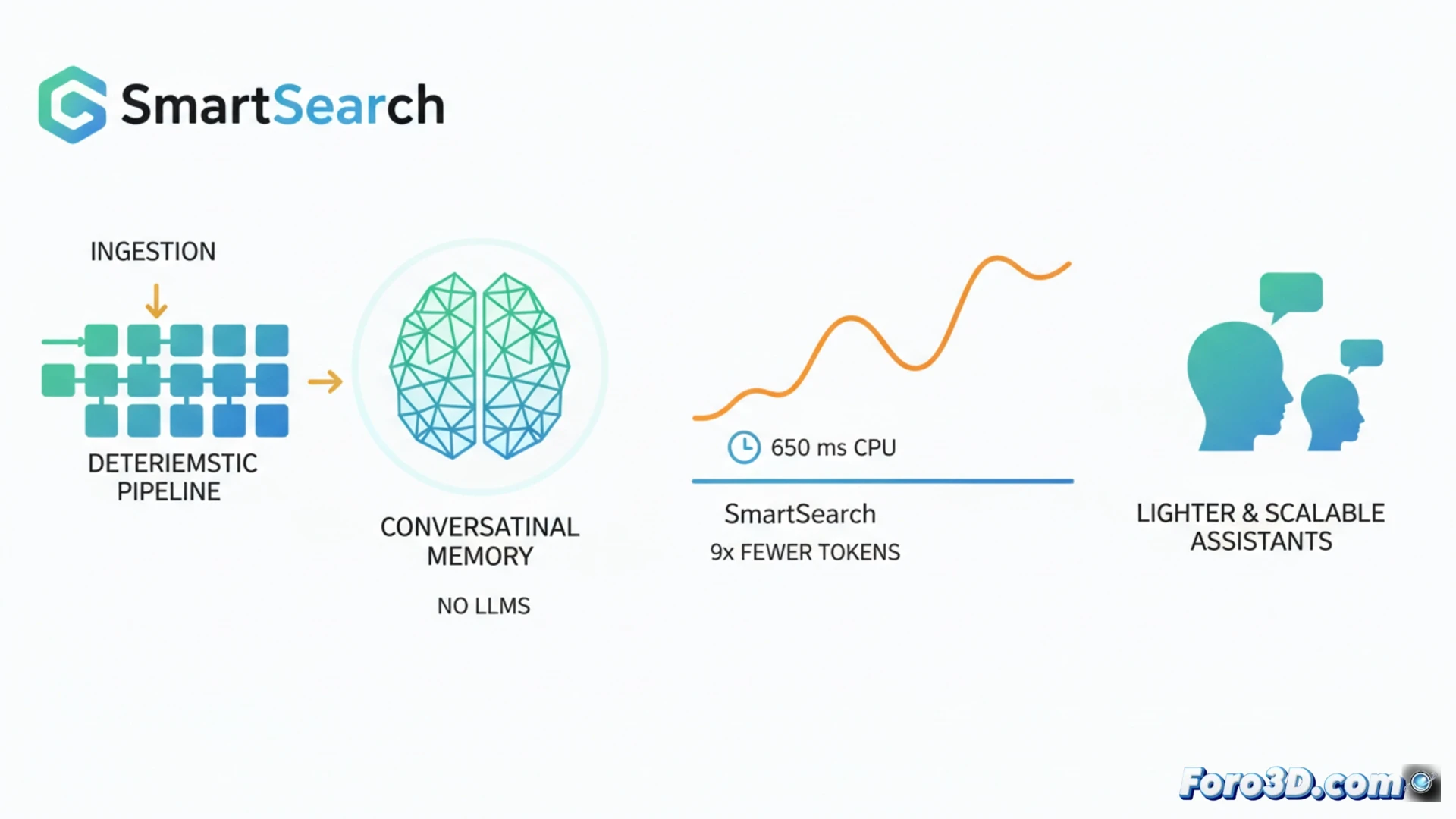
대화 검색을 위한 결정론적 파이프라인 🔍
SmartSearch는 세 가지 주요 단계로 작동합니다. 먼저, 감지된 명명된 엔티티의 관련성으로 가중된 부분 문자열 매칭을 통해 초기 검색을 수행합니다. 그런 다음, 처리되지 않은 히스토리에서 관련 엔티티를 발견하기 위해 간단한 규칙을 사용한 멀티 홉 방식으로 검색을 확장합니다. 마지막으로, 단일 학습된 구성 요소가 결과를 융합하고 재순위화합니다: CPU에서 효율적으로 실행되는 CrossEncoder+ColBERT 모델입니다. 분석에 따르면, 원시 검색은 우수하지만 병목 현상은 랭킹에 있습니다; 점수 기반 적응형 잘림 방법이 없으면 토큰을 제한할 때 대부분의 관련 증거가 손실됩니다.
더 가벼운 AI를 위한 미래의 함의 ⚡
SmartSearch의 성공은 대화형 메모리와 같은 특정 기능에 무겁고 비용이 많이 드는 아키텍처의 필요성을 의문시합니다. 수집 시점에서 LLM 의존성을 최소화하고 결정론적 효율성을 우선시함으로써, 더 접근 가능하고 지속 가능한 AI 시스템으로 가는 길을 제시합니다. 이는 자원이 제한된 장치나 낮은 지연 시간이 필요한 애플리케이션에 지능형 어시스턴트를 통합하는 데 중요하며, 현재의 거대한 컴퓨팅 발자국 없이 고급 대화 기능을 민주화합니다.
비용이 많이 드는 LLM을 사용한 수집과 구조화에 의존하지 않고 효율적이고 맥락적인 대화 메모리 시스템을 구축할 수 있을까요?
(PD: 스트라이샌드 효과 작동 중: 금지할수록 더 많이 사용됩니다, microslop처럼)