AIアシスタントのメモリ分野では、現在の傾向として、データを保存する際と取得する際の両方で大規模言語モデルを使用することが一般的です。SmartSearchはこのパラダイムに挑戦し、ほぼ完全に決定論的なパイプラインがこれらの複雑なシステムを上回ることができることを示しています。LoCoMoやLongMemEval-Sなどのベンチマークで優れた情報取得を実現し、文脈トークンを8.5倍少なく使用し、CPU上で約650 msのレイテンシで実行します。この進歩は、より軽量で高速、スケーラブルな会話型アシスタントを約束します。🤖
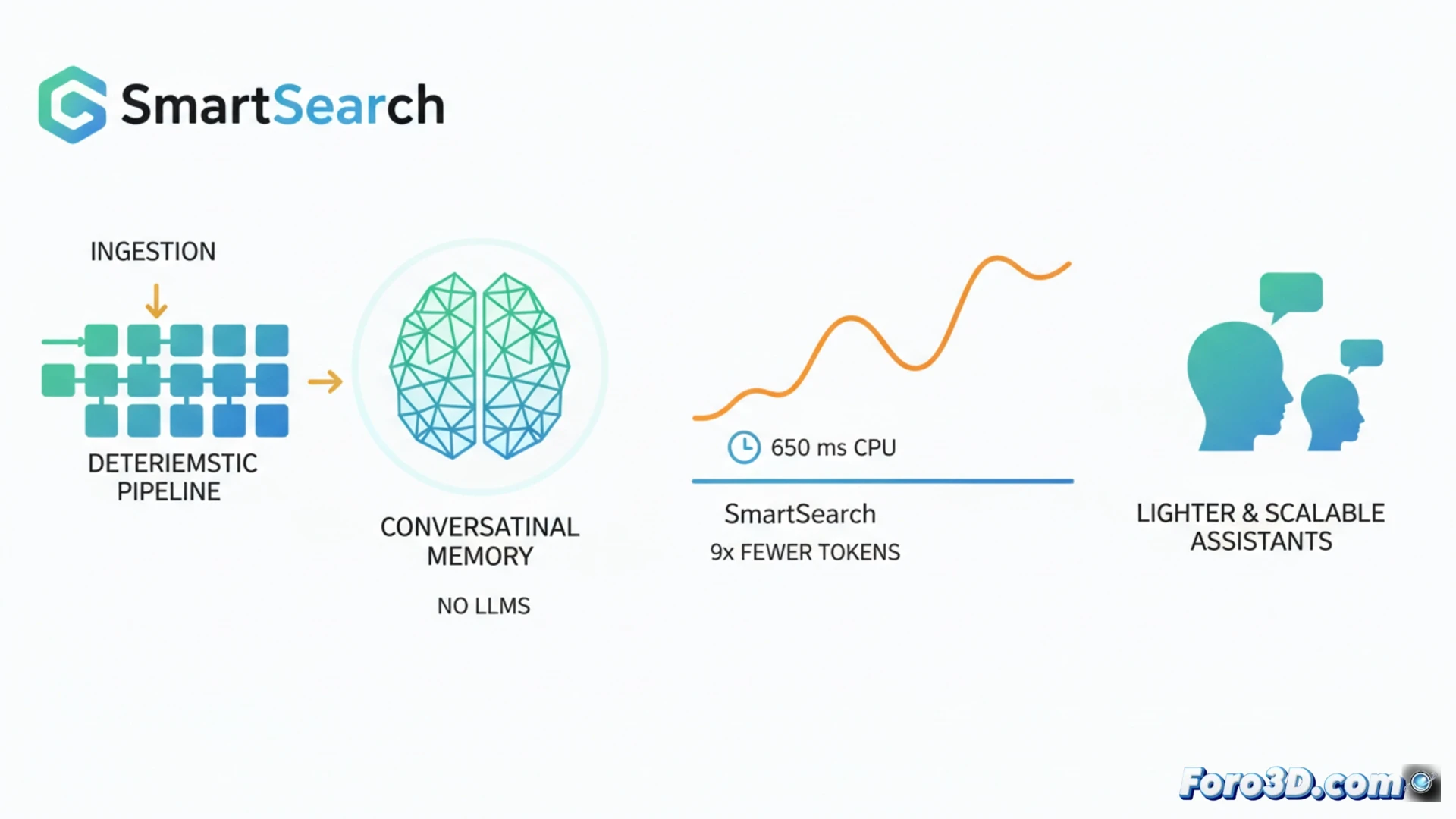
会話における取得のための決定論的パイプライン 🔍
SmartSearchは3つの主要な段階で動作します。まず、検出された固有名詞の関連性で重み付けされた部分文字列一致による初期取得を行います。次に、処理なしで履歴内の関連エンティティを発見するためのシンプルなルールを使用したマルチホップ検索を拡張します。最後に、単一の学習済みコンポーネントが結果を融合し、再ランク付けします。これはCPU上で効率的に動作するCrossEncoder+ColBERTモデルです。分析によると、生の取得は優れているものの、ボトルネックはランク付けにあり、スコアベースの適応的切り詰め手法がなければ、トークン制限により関連する証拠の大部分が失われてしまいます。
より軽量なAIの未来への示唆 ⚡
SmartSearchの成功は、会話型メモリのような特定の機能のための重厚で高価なアーキテクチャの必要性を疑問視します。取り込み時のLLM依存を最小限に抑え、決定論的効率を優先することで、よりアクセスしやすく持続可能なAIシステムへの道筋を示します。これは、リソースが限られたデバイスや低レイテンシを必要とするアプリケーションにインテリジェントアシスタントを統合する上で重要であり、現在の巨大な計算フットプリントなしに高度な会話機能を民主化します。
高価なLLMによる取り込みと構造化に依存せずに、効率的で文脈的な会話型メモリシステムを構築することは可能でしょうか?
(PD: ストレーザンド効果が発揮中: 禁止すればするほど使われる、microslopのように)