Nel campo della memoria per assistenti IA, la tendenza attuale implica l'uso di modelli di linguaggio grandi sia per strutturare i dati durante il salvataggio sia per recuperarli. SmartSearch sfida questo paradigma dimostrando che un pipeline quasi completamente deterministico può superare questi sistemi complessi. Raggiunge un recupero delle informazioni superiore in benchmark come LoCoMo e LongMemEval-S, utilizzando 8,5 volte meno token di contesto ed eseguendosi su CPU con latenze intorno ai 650 ms. Questo avanzamento promette assistenti conversazionali più leggeri, rapidi e scalabili. 🤖
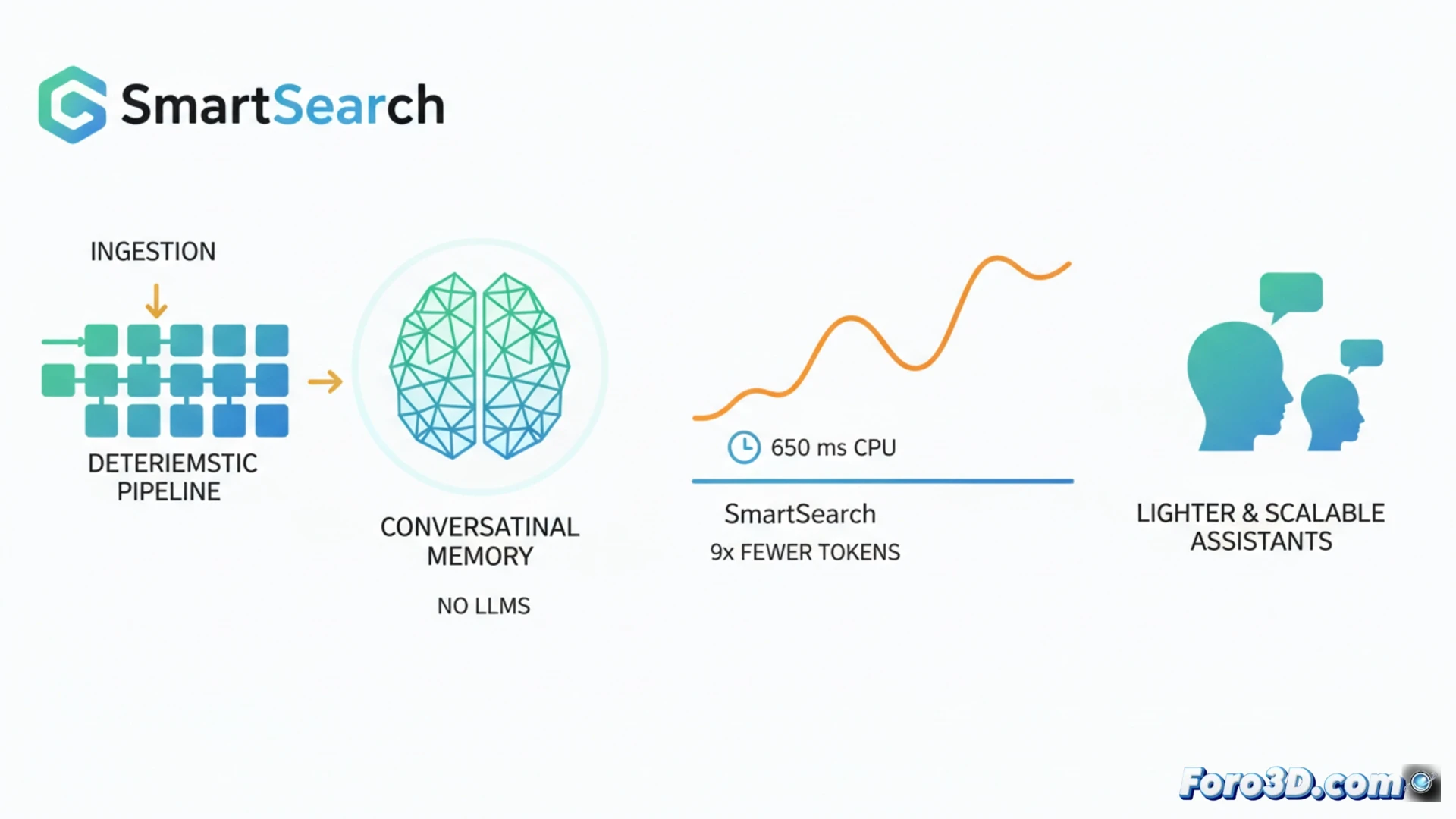
Un Pipeline Deterministico per il Recupero nelle Conversazioni 🔍
SmartSearch opera in tre fasi chiave. Primo, esegue un recupero iniziale mediante corrispondenza di sottostringhe, ponderata dalla rilevanza delle entità nominate rilevate. Poi, espande la ricerca in modo multi-hop usando regole semplici per scoprire entità correlate nella cronologia senza elaborazione. Infine, un unico componente appreso fonde e riordina i risultati: un modello CrossEncoder+ColBERT che si esegue efficientemente su CPU. L'analisi rivela che, sebbene il recupero grezzo sia eccellente, il collo di bottiglia sta nel ranking; senza il suo metodo di troncamento adattivo basato su punteggio, la maggior parte delle prove rilevanti si perderebbe limitando i token.
Implicazioni per un Futuro con IA Più Leggera ⚡
Il successo di SmartSearch mette in discussione la necessità di architetture pesanti e costose per funzioni specifiche come la memoria conversazionale. Minimizzando la dipendenza dai LLM in tempo di ingestione e priorizzando l'efficienza deterministica, stabilisce una strada verso sistemi IA più accessibili e sostenibili. Questo è cruciale per integrare assistenti intelligenti in dispositivi con risorse limitate o applicazioni che richiedono bassa latenza, democratizzando l'accesso a capacità conversazionali avanzate senza l'enorme impronta computazionale attuale.
È possibile costruire un sistema di memoria conversazionale efficiente e contestuale senza dipendere dalla costosa ingestione e strutturazione con LLM?
(PD: l'effetto Streisand in azione: quanto più lo proibisci, più lo usano, come il microslop)