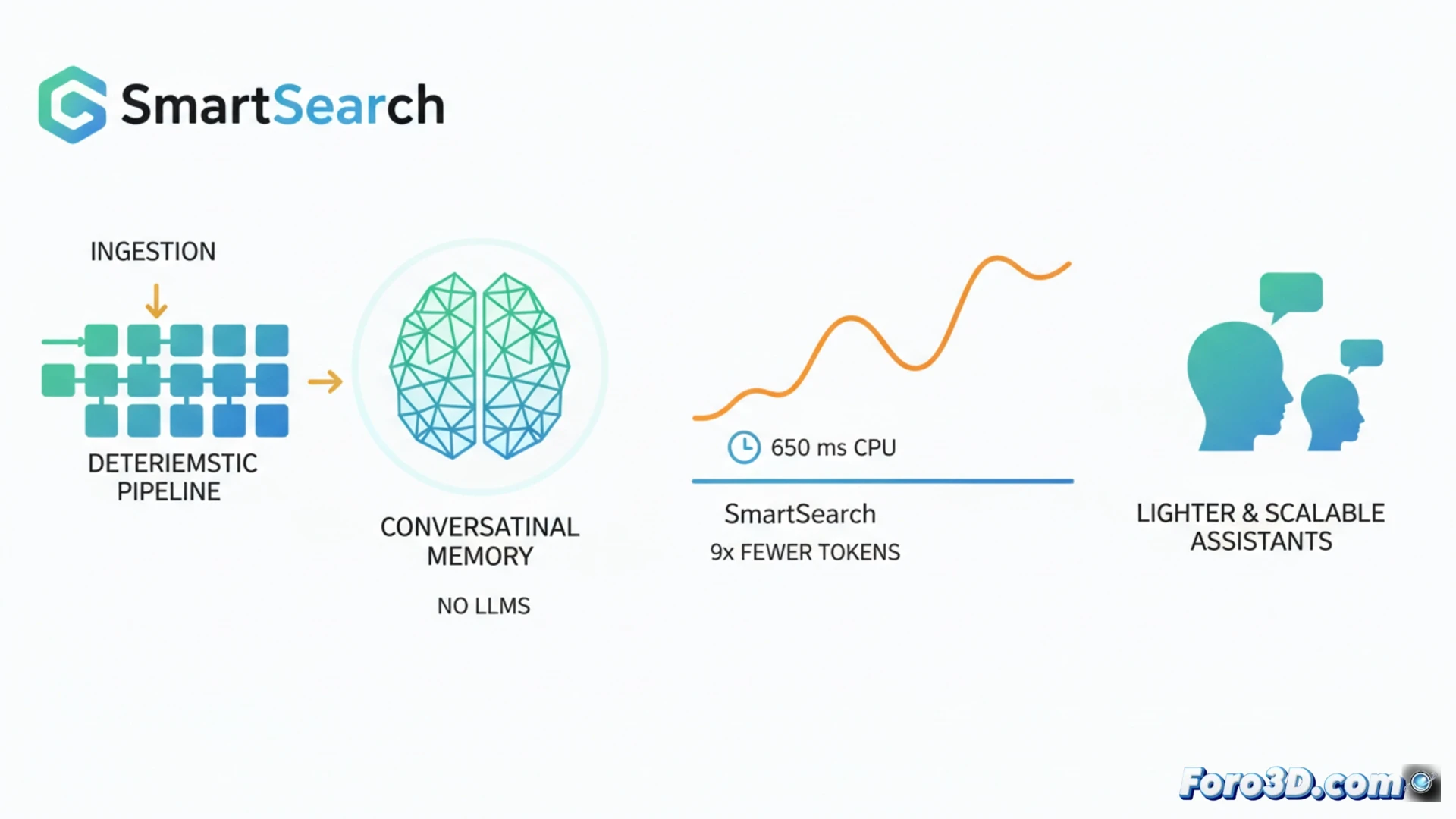
Dans le domaine de la mémoire pour assistants IA, la tendance actuelle implique d'utiliser des modèles de langage larges aussi bien pour structurer les données lors de leur stockage que pour les récupérer. SmartSearch défie ce paradigme en démontrant qu'un pipeline presque complètement déterministe peut surpasser ces systèmes complexes. Il obtient une récupération d'information supérieure sur des benchmarks comme LoCoMo et LongMemEval-S, en utilisant 8,5 fois moins de tokens de contexte et en s'exécutant sur CPU avec des latences autour de 650 ms. Cette avancée promet des assistants conversationnels plus légers, rapides et scalables. 🤖
Un Pipeline Déterministe pour la Récupération dans les Conversations 🔍
SmartSearch opère en trois étapes clés. D'abord, il effectue une récupération initiale par appariement de sous-chaînes, pondérée par la pertinence des entités nommées détectées. Ensuite, il étend la recherche de manière multi-saut en utilisant des règles simples pour découvrir des entités liées dans l'historique sans traitement. Enfin, un unique composant appris fusionne et réordonne les résultats : un modèle CrossEncoder+ColBERT qui s'exécute efficacement sur CPU. L'analyse révèle que, bien que la récupération brute soit excellente, le goulot d'étranglement réside dans le ranking ; sans sa méthode de troncature adaptative basée sur le score, la plupart des preuves pertinentes seraient perdues lors de la limitation des tokens.
Implications pour un Futur avec une IA Plus Légère ⚡
Le succès de SmartSearch remet en question la nécessité d'architectures lourdes et coûteuses pour des fonctions spécifiques comme la mémoire conversationnelle. En minimisant la dépendance aux LLMs lors de l'ingestion et en priorisant l'efficacité déterministe, il trace un chemin vers des systèmes d'IA plus accessibles et durables. Cela est crucial pour intégrer des assistants intelligents dans des dispositifs à ressources limitées ou des applications nécessitant une faible latence, démocratisant l'accès à des capacités conversationnelles avancées sans l'énorme empreinte computationnelle actuelle.
Est-il possible de construire un système de mémoire conversationnelle efficace et contextuel sans dépendre de l'ingestion et de la structuration coûteuses avec des LLMs ?
(PS : l'effet Streisand en action : plus tu l'interdis, plus on l'utilise, comme le microslop)