In the field of memory for AI assistants, the current trend involves using large language models both to structure data when storing it and to retrieve it. SmartSearch challenges this paradigm by demonstrating that a nearly completely deterministic pipeline can outperform these complex systems. It achieves superior information retrieval on benchmarks like LoCoMo and LongMemEval-S, using 8.5 times fewer context tokens and running on CPU with latencies around 650 ms. This advancement promises lighter, faster, and more scalable conversational assistants. 🤖
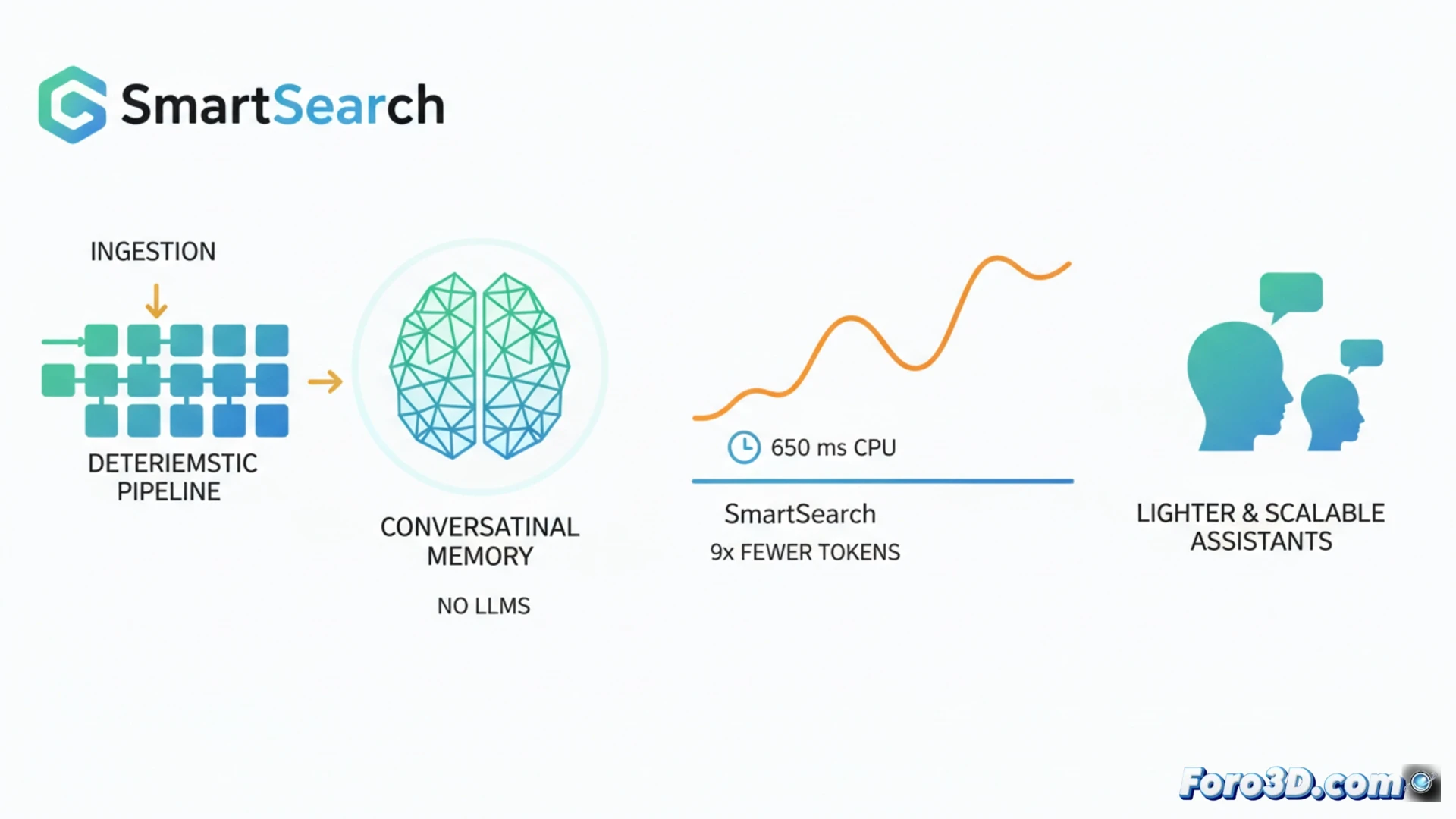
A Deterministic Pipeline for Retrieval in Conversations 🔍
SmartSearch operates in three key stages. First, it performs an initial retrieval through substring matching, weighted by the relevance of detected named entities. Then, it expands the search in a multi-hop manner using simple rules to discover related entities in the history without processing. Finally, a single learned component fuses and reranks the results: a CrossEncoder+ColBERT model that runs efficiently on CPU. The analysis reveals that, while raw retrieval is excellent, the bottleneck is in ranking; without its adaptive score-based truncation method, most relevant evidence would be lost when limiting tokens.
Implications for a Future with Lighter AI ⚡
The success of SmartSearch questions the need for heavy and costly architectures for specific functions like conversational memory. By minimizing reliance on LLMs at ingestion time and prioritizing deterministic efficiency, it paves the way toward more accessible and sustainable AI systems. This is crucial for integrating intelligent assistants into resource-limited devices or applications that require low latency, democratizing access to advanced conversational capabilities without the current enormous computational footprint.
Is it possible to build an efficient and contextual conversational memory system without relying on costly ingestion and structuring with LLMs?
(P.S.: the Streisand effect in action: the more you prohibit it, the more they use it, like microslop)