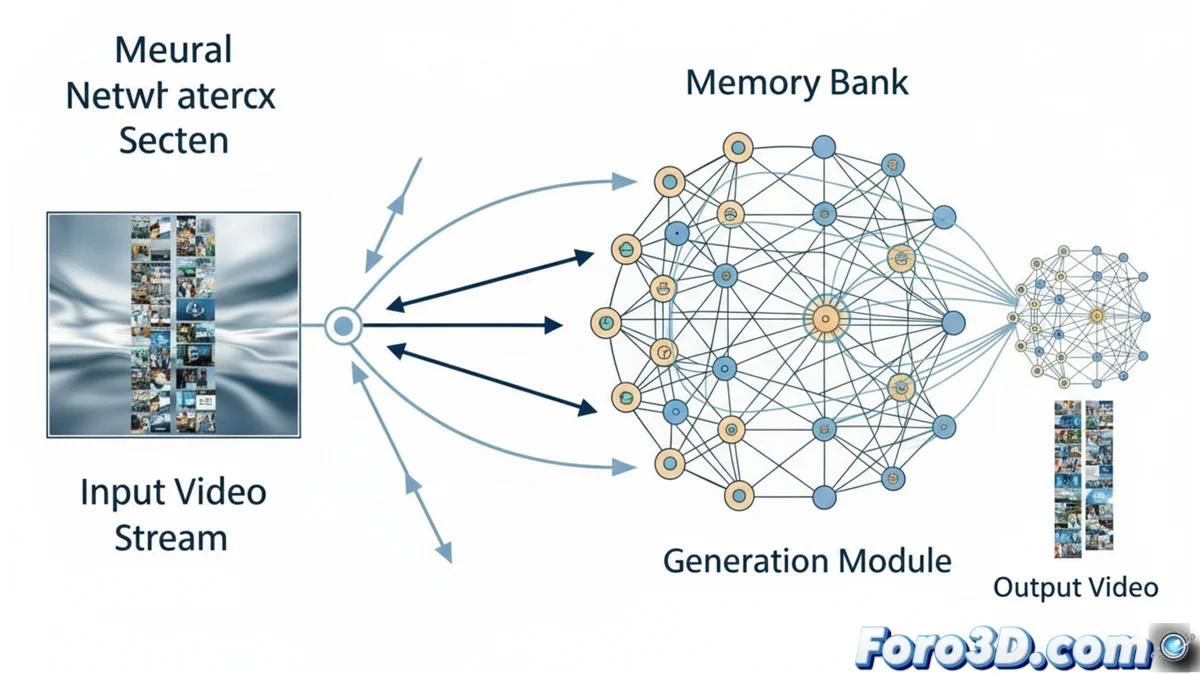
MemFlowは視覚的一貫性を保ちながら長い動画を生成
長く一貫した動画シーケンスを作成することは重要な技術的課題です。従来の方法は過去を圧縮するための硬直的な戦略を使用し、多様な視覚的手がかりを参照する能力を制限します。MemFlowは、モデルが歴史的な情報をどのように記憶し使用するかを最適化する動的なアプローチを導入します。🎬
コンテキストに適応するメモリバンク
MemFlowの中心的な革新は、インテリジェントに更新されるメモリシステムです。新たな動画フラグメントを生成する前に、システムはそのフラグメントに関連付けられた記述テキストを分析します。この情報により、データベースから最も関連性の高い過去のフレームを自動的に取得します。このプロセスは、正確な視覚コンテキストを特定するだけでなく、新しいイベントが発生したりシーンが大幅に変化したりした場合でも、意味論的なスムーズなトランジションを可能にします。
動的システムの主な利点:- コンテキスト精度:固定ウィンドウに依存するのではなく、本当に必要な過去の視覚情報を発見します。
- スムーズなトランジション:アクションや環境の急激な変化でも、ナラティブと視覚の連続性を維持します。
- 実装の柔軟性:キー・バリューのキャッシュを使用するストリーミング動画生成モデルに互換性があります。
MemFlowは最小限の計算負荷で長いコンテキストで卓越した一貫性を達成し、メモリなしのベースモデルと比較して速度をわずか7.9%低下させるだけです。
最大効率のための選択的活性化
生成フェーズ中、モデルは効率的でなければなりません。MemFlowは必要な要素のみを活性化することでこれに対処します。モデルの注意層で、各クエリに対して、メモリバンクに保存された最も関連性の高いトークンのみが活性化されます。この選択的注意メカニズムは、無関係なデータを処理することを避け、システムの機敏性を維持します。
効率的なプロセスの仕組み:- 指向性クエリ:モデルは現在のフラグメントに重要な情報のみをメモリから検索します。
- 最適化された計算:全歴史的メモリを活性化しないことで、処理リソースを節約します。
- 一貫した結果:時間を通じて統一された視覚ナラティブを維持しつつ、高品質な動画を生成します。
一貫した動画生成の未来
MemFlowは長時間のストリーミング動画生成のための実践的な進歩を表します。静的メモリ方法をテキストガイド付きの動的メモリに置き換えることで、長大なシーケンスの根本的な非一貫性問題を解決します。次に生成動画のキャラクターがショット間で説明不能に属性を変える場合、こうしたシステムを採用することで解決するかもしれません。その設計は視覚品質と運用効率を完璧にバランスさせています。🚀