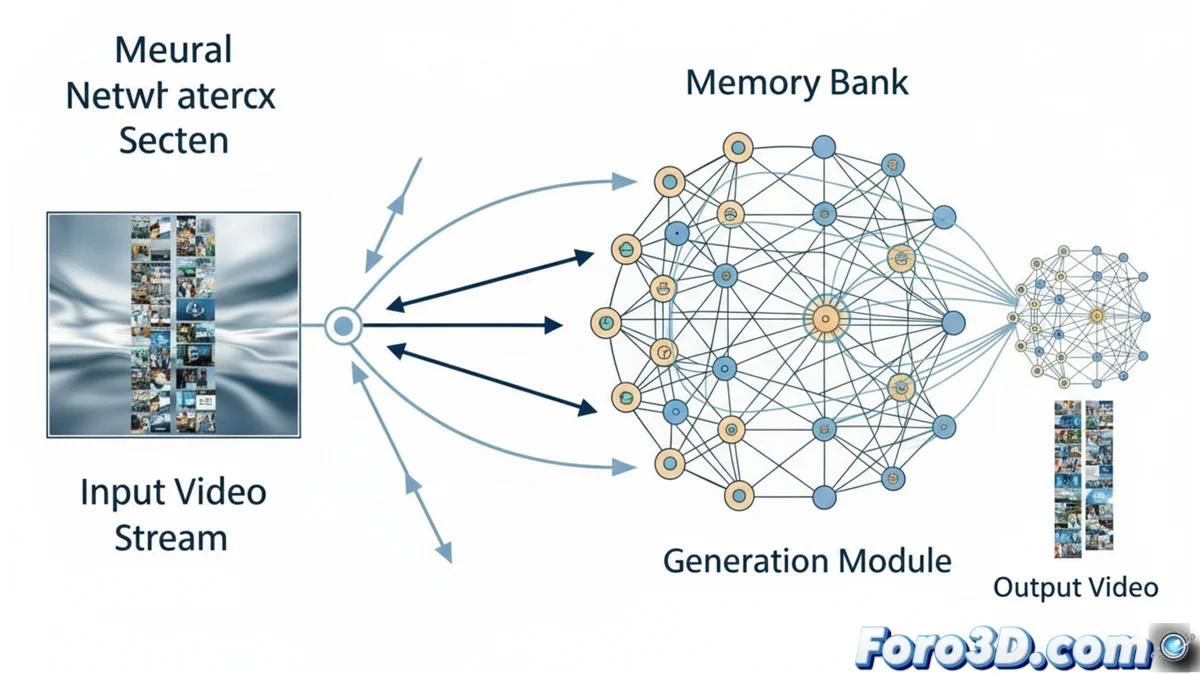
MemFlow genera video lunghi mantenendo la coerenza visiva
Creare sequenze video estese e coerenti è una sfida tecnica importante. I metodi tradizionali usano solitamente strategie rigide per comprimere il passato, limitando la loro capacità di riferirsi a indizi visivi diversi. MemFlow introduce un approccio dinamico che ottimizza come un modello ricorda e usa informazioni storiche. 🎬
Un banco di memoria che si adatta al contesto
L'innovazione centrale di MemFlow è il suo sistema di memoria che si aggiorna in modo intelligente. Prima di produrre un nuovo frammento di video, il sistema analizza il testo descrittivo associato a quel frammento. Con questa informazione, recupera automaticamente i frame storici più rilevanti dal suo database. Questo processo non solo localizza il contesto visivo preciso, ma permette anche transizioni semantiche fluide quando appaiono nuovi eventi o la scena cambia in modo significativo.
Vantaggi chiave del sistema dinamico:- Precisione contestuale: Trova l'informazione visiva passata di cui ha realmente bisogno, invece di dipendere da una finestra fissa.
- Transizioni fluide: Mantiene la continuità narrativa e visiva anche con cambiamenti improvvisi nell'azione o nell'ambiente.
- Flessibilità di implementazione: È compatibile con qualsiasi modello di generazione video in streaming che utilizzi una cache di chiavi e valori.
MemFlow raggiunge una coerenza eccezionale in contesti lunghi con un carico computazionale minimo, riducendo la velocità solo del 7,9% rispetto a un modello base senza memoria.
Attivazione selettiva per massima efficienza
Durante la fase di generazione, il modello deve essere efficiente. MemFlow affronta questo attivando solo gli elementi necessari. Negli strati di attenzione del modello, per ogni query, si attivano solo i token più rilevanti memorizzati nel banco di memoria. Questo meccanismo di attenzione selettiva evita di processare dati irrilevanti, mantenendo l'agilità del sistema.
Come funziona il processo efficiente:- Query mirata: Il modello cerca nella memoria solo l'informazione cruciale per il frammento attuale.
- Calcolo ottimizzato: Evitando di attivare tutta la memoria storica, si conservano risorse di elaborazione.
- Risultato coerente: Si genera video di alta qualità mantenendo una narrativa visiva unificata nel tempo.
Il futuro della generazione video coerente
MemFlow rappresenta un progresso pratico per la generazione video in streaming di lunga durata. Sostituendo i metodi di memoria statici con uno dinamico e guidato dal testo, risolve il problema fondamentale dell'incoerenza in sequenze estese. La prossima volta che un personaggio nel tuo video generato cambierà inspiegabilmente attributi tra inquadrature, la soluzione potrebbe essere adottare un sistema come questo. Il suo design bilancia perfettamente qualità visiva e efficienza operativa. 🚀