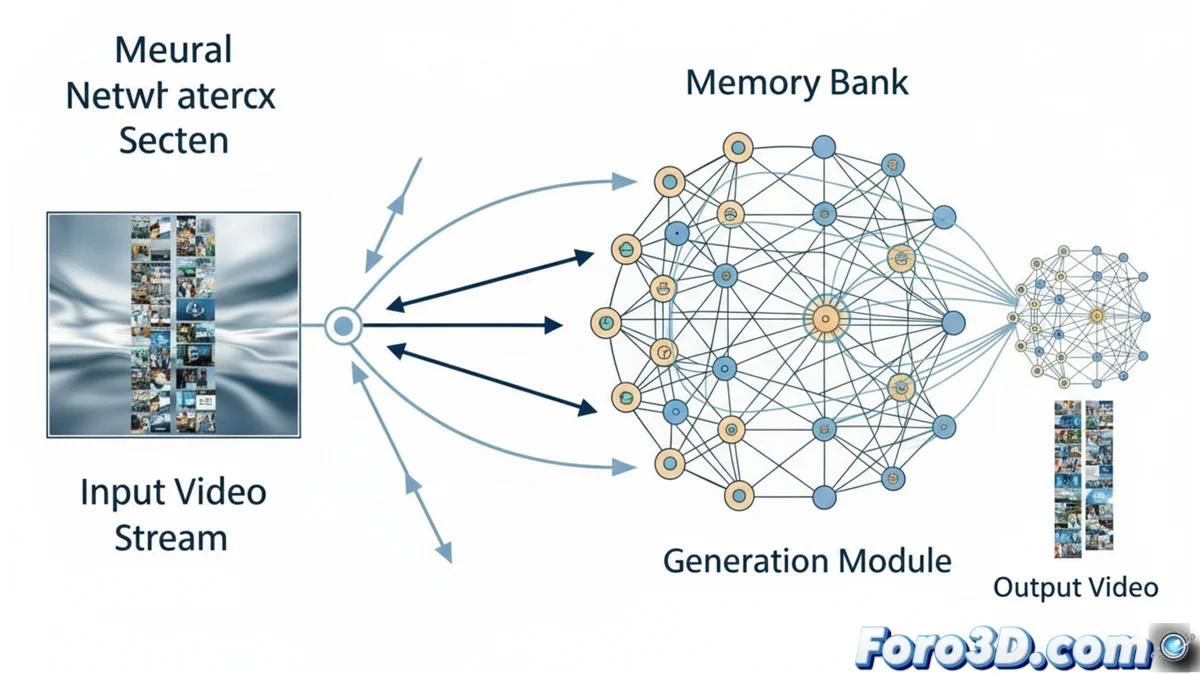
MemFlow génère des vidéos longues en maintenant la cohérence visuelle
Créer des séquences vidéo étendues et cohérentes est un défi technique important. Les méthodes traditionnelles utilisent généralement des stratégies rigides pour compresser le passé, ce qui limite leur capacité à référencer des indices visuels divers. MemFlow introduit une approche dynamique qui optimise la façon dont un modèle se souvient et utilise les informations historiques. 🎬
Une banque de mémoire qui s'adapte au contexte
L'innovation centrale de MemFlow est son système de mémoire qui se met à jour de manière intelligente. Avant de produire un nouveau fragment de vidéo, le système analyse le texte descriptif associé à ce fragment. Avec cette information, il récupère automatiquement les photogrammes historiques les plus pertinents de sa base de données. Ce processus non seulement localise le contexte visuel précis, mais permet également des transitions sémantiques fluides lorsque de nouveaux événements apparaissent ou que la scène change de manière significative.
Avantages clés du système dynamique :- Précision contextuelle : Trouve les informations visuelles passées vraiment nécessaires, au lieu de dépendre d'une fenêtre fixe.
- Transitions fluides : Maintient la continuité narrative et visuelle même avec des changements brusques dans l'action ou l'environnement.
- Flexibilité d'implémentation : Compatible avec tout modèle de génération de vidéo en streaming utilisant un cache de clés et de valeurs.
MemFlow atteint une cohérence exceptionnelle dans des contextes longs avec une charge computationnelle minimale, réduisant la vitesse seulement de 7,9 % par rapport à un modèle de base sans mémoire.
Activation sélective pour une efficacité maximale
Pendant la phase de génération, le modèle doit être efficace. MemFlow aborde cela en activant uniquement les éléments nécessaires. Dans les couches d'attention du modèle, pour chaque requête, seuls les tokens les plus pertinents stockés dans la banque de mémoire sont activés. Ce mécanisme d'attention sélective évite de traiter des données non pertinentes, ce qui maintient l'agilité du système.
Comment fonctionne le processus efficace :- Requête dirigée : Le modèle recherche dans la mémoire uniquement les informations cruciales pour le fragment actuel.
- Calcul optimisé : En évitant d'activer toute la mémoire historique, les ressources de traitement sont préservées.
- Résultat cohérent : Une vidéo de haute qualité est générée en maintenant une narration visuelle unifiée au fil du temps.
L'avenir de la génération de vidéo cohérente
MemFlow représente une avancée pratique pour la génération de vidéo en streaming de longue durée. En remplaçant les méthodes de mémoire statiques par une dynamique guidée par le texte, il résout le problème fondamental de l'incohérence dans les séquences étendues. La prochaine fois qu'un personnage dans votre vidéo générée changera inexplicablement d'attributs entre les plans, la solution pourrait être d'adopter un système comme celui-ci. Son design équilibre parfaitement qualité visuelle et efficacité opérationnelle. 🚀