MemFlow 生成长视频并保持视觉连贯性
创建长而连贯的视频序列是一个重要的技术挑战。传统方法通常使用刚性的策略来压缩过去,这限制了它们引用多样视觉线索的能力。MemFlow 引入了一种动态方法,优化了模型如何回忆和使用历史信息。🎬
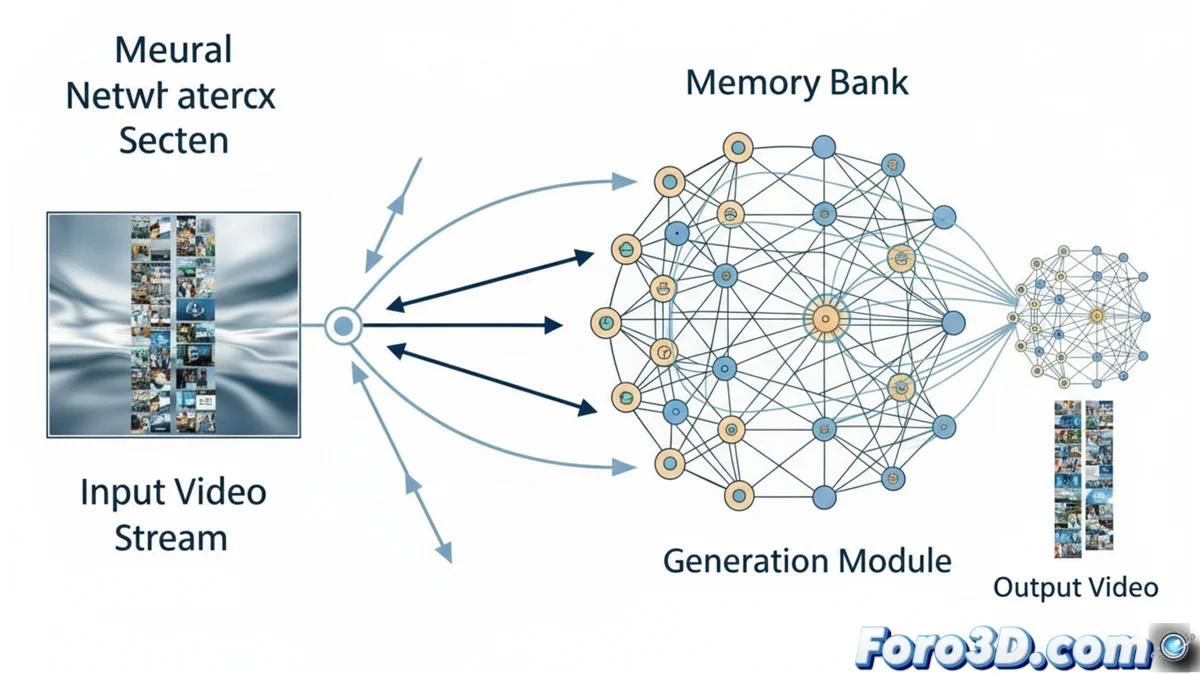
适应上下文的记忆库
MemFlow 的核心创新是其智能更新的记忆系统。在生成新视频片段之前,系统分析与该片段关联的描述性文本。利用此信息,它自动从数据库中检索最相关的历史帧。此过程不仅精确定位视觉上下文,还允许在出现新事件或场景显著变化时实现流畅的语义过渡。
动态系统的关键优势:- 上下文精度: 找到真正需要过去的视觉信息,而不是依赖固定窗口。
- 平滑过渡: 即使动作或环境发生突然变化,也保持叙事和视觉连续性。
- 实现灵活性: 兼容任何使用键值缓存的流式视频生成模型。
MemFlow 在长上下文下实现了卓越的连贯性,同时计算负载最小,与无记忆的基线模型相比,仅降低速度 7.9%。
选择性激活以实现最大效率
在生成阶段,模型必须高效。MemFlow 通过仅激活必要元素来解决此问题。在模型的注意力层中,对于每个查询,仅激活存储在记忆库中的最相关标记。这种选择性注意力机制避免处理无关数据,从而保持系统的敏捷性。
高效过程的工作原理:- 定向查询: 模型仅在记忆中搜索当前片段的关键信息。
- 优化计算: 通过避免激活所有历史记忆,节省处理资源。
- 连贯结果: 生成高质量视频,同时保持随时间统一的视觉叙事。
一致视频生成的未来
MemFlow 代表了长时流式视频生成的实用进步。通过用动态、文本引导的记忆方法取代静态记忆方法,它解决了长序列中连贯性的根本问题。下次当你生成的视频中角色在镜头间莫名其妙地改变属性时,解决方案可能在于采用像这样的系统。其设计完美平衡了视觉质量和操作效率。🚀