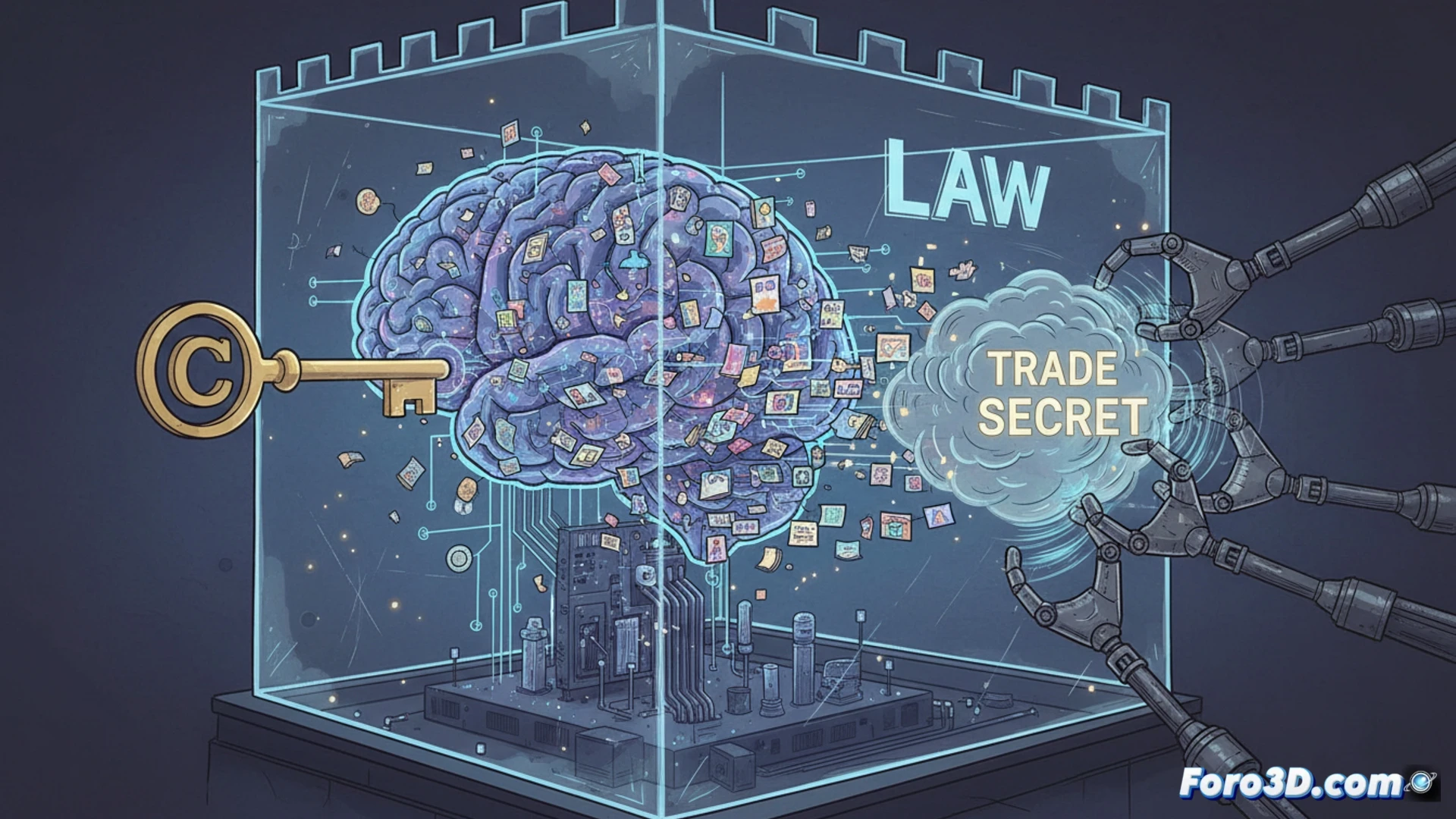
La normativa actual exige que los modelos de inteligencia artificial respeten los derechos de autor, pero no obliga a las grandes tecnológicas a revelar las obras usadas en su entrenamiento. Esto genera una contradicción legal: es imposible verificar si se cumple la ley cuando los datos de origen permanecen ocultos tras acuerdos de confidencialidad y secretos comerciales.
Trazabilidad obligatoria: la clave técnica para un ecosistema justo 🔍
La solución técnica es imponer un sistema de trazabilidad pública y obligatoria sobre los datasets de entrenamiento. Cada obra utilizada debería registrarse en un repositorio verificable, con metadatos que identifiquen al creador y la licencia. Esto permitiría auditorías externas y sistemas de compensación automática. Sin esta transparencia, cualquier reclamo legal es una carrera de obstáculos donde el demandante debe adivinar qué datos usó la máquina.
El truco del mago: ahora la IA te copia, pero no te dice cómo 🎩
Las grandes tecnológicas parecen magos de feria: te piden que confíes en ellos mientras esconden la chistera. Dicen que revelar sus datos de entrenamiento sería como pedirle a Coca-Cola la receta secreta. Pero si la ley exige respeto a los derechos de autor, el truco debería ser público. Mientras tanto, los creadores miran cómo sus obras se usan sin permiso y sin saber si recibirán algo más que un like de la inteligencia artificial.