Google ha compartido información técnica sobre el funcionamiento interno de su sistema de rastreo. Se confirma que Googlebot no es una entidad única, sino un cliente más dentro de una plataforma centralizada usada por varios servicios. Un dato clave es el límite estricto de 2MB para el HTML de una URL, incluidas las cabeceras HTTP. Superar este tamaño provoca que el contenido sea truncado. Esta información es vital para desarrolladores y expertos en SEO que buscan optimizar la indexación.
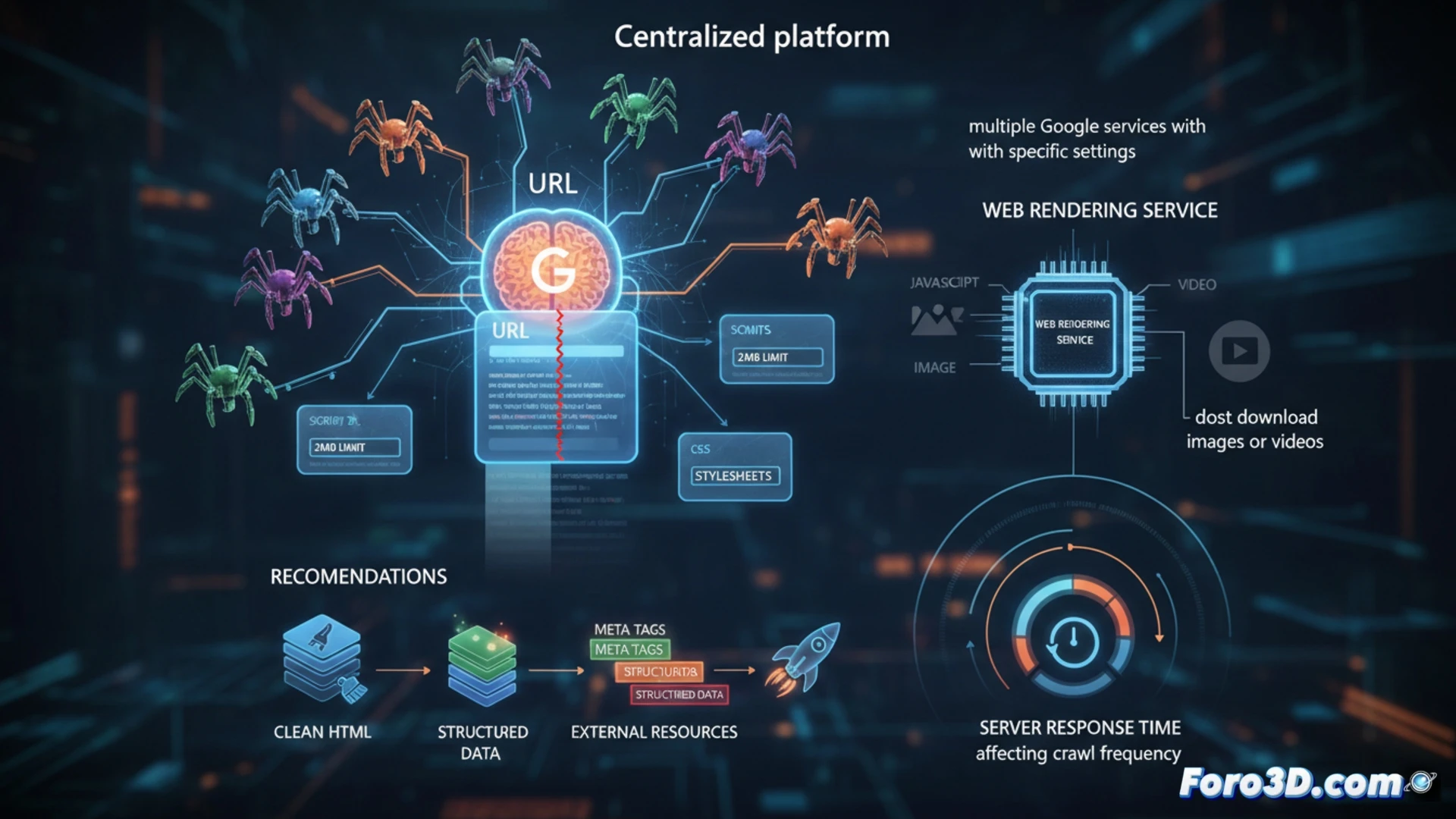
Límites técnicos y procesamiento de recursos externos 🤖
El límite de 2MB se aplica de forma individual a cada recurso externo solicitado, como archivos CSS y JavaScript. El Web Rendering Service (WRS) se encarga de procesar el JS y CSS para renderizar la página, pero no descarga medios como imágenes o vídeos. Google enfatiza la necesidad de un HTML limpio, colocando metaetiquetas y datos estructurados en la parte superior. Además, los tiempos de respuesta del servidor son un factor crítico, ya que influyen directamente en la frecuencia con la que Googlebot rastrea un sitio.
Tu HTML de 10MB le da dolor de cabeza a Googlebot 🤯
Parece que la época de enviar novelas enteras en código HTML ha terminado. Si tu página supera el límite, Googlebot simplemente deja de leer, como un estudiante abrumado por un tomo infinito. Así que olvida ese CSS embebido de 5000 líneas o ese script monolítico justo al inicio. La recomendación es clara: ser conciso. Podríamos decir que Google prefiere la poesía técnica a la prosa inflada. Un buen ejercicio es imaginar que cada kilobyte extra es un ladrillo en la mochila del rastreador.